Review
Prodigy is designed to make it easy to collect labelled data. However, the goal of Prodigy isn’t just about getting data labelled; it’s also about getting the data right. That means that at some point, if you’re working with multiple annotators, you’ll want to review the annotations that they produce.
The goal of this document is to help explain how you can review data in Prodigy
via the review recipe and also to demonstrate some use-cases to help you
get started quickly.
Quickstart
Prodigy supports reviewing annotations via the review recipe. This recipe
can handle a lot of use-cases but in order to get the data in the right format
it can be helpful to understand some of the details under the hood.
If you’d like to start by reading the motivation behind reviewing annotations you’ll want to start here. If you’re more interested in understanding the technical requirements you may want to start here.
This document highlights a few examples worth looking at.
- The binary text-classification example demonstrates
how to use
reviewin a binary text classification setup. This example demonstrates a lot of details that may be helpful when you’re first trying out this recipe. - The choice example demonstrates how to use
reviewin a multi-label binary text classification setup. - The NER example demonstrates how to use
reviewin a multi-label binary text classification setup.
In version 1.13.1, Prodigy added support for recipes that can add annotations to a dataset from a model, as-if they were done by an annotator. This effectively allows you to review examples where models disagree, which may be interesting examples to evaluate.
These recipes include ner.model-annotate, spans.model-annotate and
textcat.model-annotate. If you’d like to see an example on how to use
these recipes, check out the
models as annotators section.
Why review?
Before diving into the review recipe, it may help to remind ourselves why
it’s important to take annotation reviews seriously.
-
If your annotators don’t agree on a particular example, it may be a bad to use that example to train machine learning models. Reviewing these examples will allow you to prevent that from happening.
-
If your annotators don’t agree often, it may provide an indication that your annotations process needs to be improved. It may be that the instructions are unclear, or that a label needs to be reconsiderd. But without reviewing the annotations you may not become aware of these issues.
-
During a review you can choose to focus on the examples where annotators disagree. This usually will provide you with interesting examples that you can save for discussion during a team meeting. Examples with disagreement are usually a great vehicle for a discussion that helps the team agree on the edge cases.
Annotations in Prodigy
To understand how reviews work in Prodigy, it also helps to take a step back to reflect on what we need in order to perform a review. First, we need multiple annotators and we need to route examples to them.
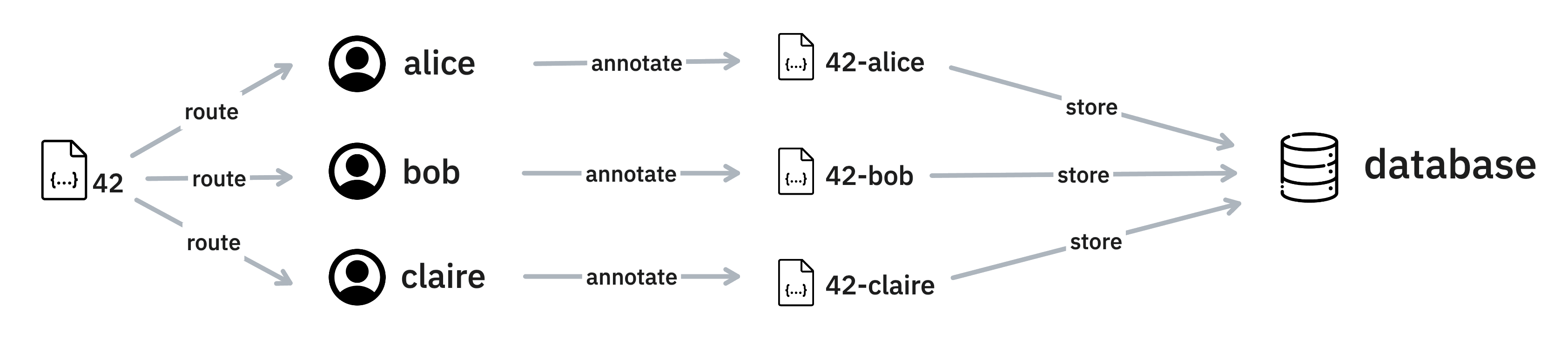
Once the annotators save their annotations we can prepare a stream for review. To do this right, we want to be able to group the original annotations so that we may see what each annotator thought of the example.

But grouping isn’t enough! In order to understand what the annotators did we also need to be able to reconstruct the original example. If we cannot reconstruct the original example we also won’t be able to render what the users originally saw, which also makes it much harder to do a proper review.
There are a lot of little details in order to do this right. So let’s deconstruct some of the moving parts in Prodigy to understand this better. First, let’s think about what happens when you start a Prodigy recipe.

When a Prodigy recipe starts it typically reads data from disk which it can then turn into a format that works for the annotation interface that you’re interested in using. The backend will attach a corresponding view_id to the example that refers to the annotation interface that was used to annotate the current example together with any input data that it needs.
Independent of the annotation interface the Prodigy backend should also add two hashes to each annotation example: an input_hash and a task_hash. These hashes can be seen as unique identifiers for the example and based on these hashes Prodigy is able to determine whether two examples are duplicates.
You can learn more about these hashes by reading this section but the important thing for now is to acknowledge that these hashes are relevant when you’re reviewing. During a review, you want to collect identical examples from different annotators and Prodigy uses these hashes to find the right sets to collect. That also means that if you’re working with custom recipes you’ll want to remain concious of how you create these hashes, because they define what it means for an example to be unique during a review.
Finally, we also shouldn’t forget about any extra settings that may have
been configured. These could be configured by the recipe itself, or by a
prodigy.json configuration file. Some of these
settings are purely aesthetic, like changes to CSS. But other settings,
especially the interface-specific settings, can have a big impact in how the
annotation interface behaves. For an example, check
these settings for the choice
interface.
Let’s now move on to reflect on what happens when a user actually starts annotating data.
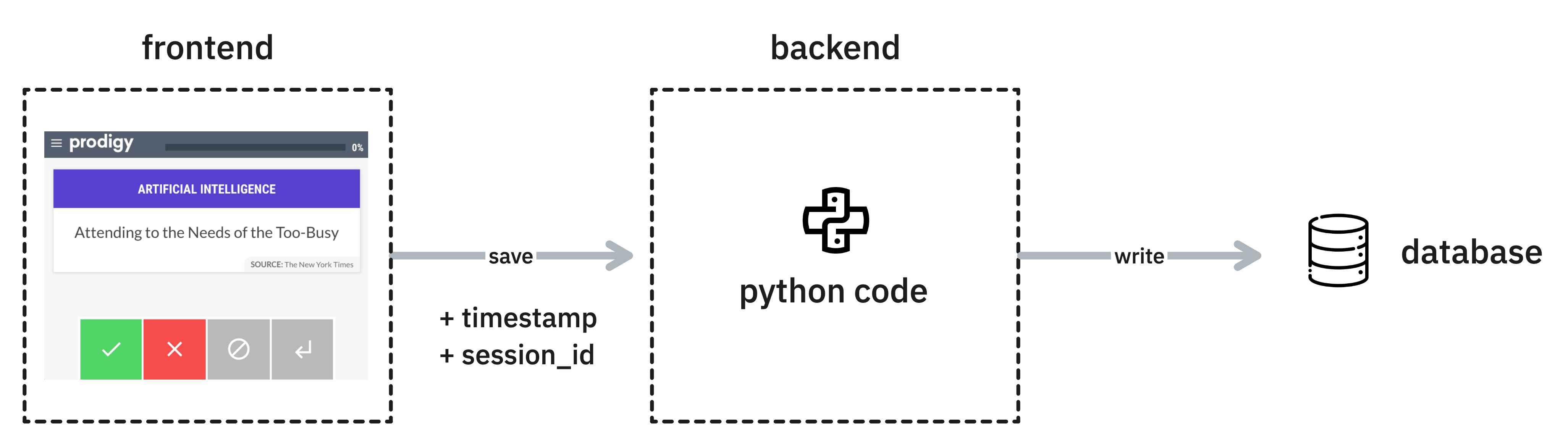
After a while, a user will have annotated a batch of data. This is sent to the backend when the user hits “save”. This batch will contain the annotations, as well as two extra pieces of information: a timestamp key and session identifier keys. The timestamp key is typically relevant when you’re calculating metrics over your annotations and the session identifier represents the user that is annotating the examples. It’s these session identifiers that are very relevant to the reviews.
There’s a small caveat with regards to the session identifier that’s worth diving into. Prodigy can be run with predefined users together with task routers that determine who will annotate each example. But it can also be configured to run with no session identifier. In these cases Prodigy will generate a session name based on the timestamp during the start of the recipe.
Runing Prodigy without a session name can be fine if you’re using Prodigy personally but it does mean that you will need to add session identifiers after the fact if you are interested in reviewing annotations later. If you know that you’ll be annotating with a group, we recommend thinking about session names early and that you ensure that these names don’t need to change over time.
For the examples in this guide we’ll assume that you’re annotating in a
multi-user setup and that the session is provided via /?session= in the
URL. If you’re eager to learn more about how to configure such a multi-user
setup, we recommend reading the task routers guide for
more details.
Eventually you’ll get examples in your database that may look something like this:
Snapshot of an annotated example{
"text": "Attending to the Needs of the Too-Busy",
"label": "artificial intelligence",
"answer": "accept",
"meta": {
"source": "The New York Times"
},
"_input_hash": -917064880,
"_task_hash": -1067504772,
"_timestamp": 1692104673,
"_annotator_id": "<dataset-name>-<username>",
"_session_id": "<dataset-name>-<username>",
"_view_id": "classification"
...
}
The precise output may look a bit different depending on the recipe that you’re using but the relevant components that matter to a review deserve to be mentioned explicitly:
- The
_input_hashand_task_hashbecause these define the uniqueness of the annotation example. Without these Prodigy cannot find the annotations from other users that annotated the same example. - The
_session_idand_annotator_idbecause these define who annotated the example. These two keys should always be equal to each other and should contain both the name of the dataset as well as the name passed in the/?session=part of the URL. - The
_view_idbecause it defines the user interface, which thereviewrecipe will need to render the annotations. - Typically, the other keys in this JSON dictionary are important because they
are needed to construct the annotation interface. The
_view_iddetermines which keys are required but it’s good to remember that the recipe may produce extra keys that the UI does not need. These extra keys may have been added by a custom recipe because they are useful to store for analytics but they won’t be shown in a review interface.
All of these features are important to be able to reconstruct the examples for
review. However, there’s one thing that the database does not store: the
settings from the prodigy.json file that was used at the time of annotating.
This is why we advise to be conservative about your configuration file and you
don’t accidentally delete it. The review recipe may need it in order to
properly reconstruct the UI that the annotators saw.
Example: Reviews for binary text classification.
Let’s now give the review recipe a spin by using it to review text
classification examples. We’ll also need some data to annotate so we’ll re-use
the news_headlines.jsonl dataset for this which can be downloaded via the link
below:
Next, we’ll annotate some examples by using the textcat.manual recipe
that’s configured to receive annotations from three annotators. This is
configured via the environment variables.
Recipe command
PRODIGY_CONFIG_OVERRIDES='{"feed_overlap": true}' PRODIGY_ALLOWED_SESSIONS=alice,bob,claire prodigy textcat.manual textcat_news_headlines ./news_headlines.jsonl --label "artificial intelligence"
This command will start the Prodigy recipe and users can access it providing
their session name in the URL. This
recipe uses the classification interface under the hood when there is
only one label to select, which gives the user a
binary annotation mechanism. This
means that the user can only provide answers by accepting, rejecting or ignoring
each example. The generated interface will look like this:
Prodigy
As an example, let’s now pretend that the users start annotating. You can do this manually if you’d like to follow along but alternatively you may also download pre-annotated data to see the effect.
Here’s what the data could look like when it is exported via the db-out
recipe. It contains six random annotations from three users (alice, bob and
claire).
{"text":"In Silicon Valley, a Voice of Caution Guides a High-Flying Uber","meta":{"source":"The New York Times"},"_input_hash":-1886037109,"_task_hash":-332936186,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283710,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"How Silicon Valley Pushed Coding Into American Classrooms","meta":{"source":"The New York Times"},"_input_hash":1842734674,"_task_hash":-1664806480,"label":"artificial intelligence","_view_id":"classification","answer":"reject","_timestamp":1692283711,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"Silicon Valley Investors Flexed Their Muscles in Uber Fight","meta":{"source":"The New York Times"},"_input_hash":10406310,"_task_hash":58752667,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283711,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"Prodigy, for machine teaching. It's made by spaCy people. Another sentence, yo.","_input_hash":-1584346565,"_task_hash":-2142900962,"label":"artificial intelligence","_view_id":"classification","answer":"reject","_timestamp":1692283712,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"Uber\u2019s Lesson: Silicon Valley\u2019s Start-Up Machine Needs Fixing","meta":{"source":"The New York Times"},"_input_hash":1886699658,"_task_hash":-234409469,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283712,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"\u2018The Internet Is Broken\u2019: @ev Is Trying to Salvage It","meta":{"source":"The New York Times"},"_input_hash":1569967905,"_task_hash":554311543,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283714,"_annotator_id":"textcat_news_headlines-alice","_session_id":"textcat_news_headlines-alice"}
{"text":"In Silicon Valley, a Voice of Caution Guides a High-Flying Uber","meta":{"source":"The New York Times"},"_input_hash":-1886037109,"_task_hash":-332936186,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283719,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"How Silicon Valley Pushed Coding Into American Classrooms","meta":{"source":"The New York Times"},"_input_hash":1842734674,"_task_hash":-1664806480,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283720,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"Silicon Valley Investors Flexed Their Muscles in Uber Fight","meta":{"source":"The New York Times"},"_input_hash":10406310,"_task_hash":58752667,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283720,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"Prodigy, for machine teaching. It's made by spaCy people. Another sentence, yo.","_input_hash":-1584346565,"_task_hash":-2142900962,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283720,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"Uber\u2019s Lesson: Silicon Valley\u2019s Start-Up Machine Needs Fixing","meta":{"source":"The New York Times"},"_input_hash":1886699658,"_task_hash":-234409469,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283721,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"\u2018The Internet Is Broken\u2019: @ev Is Trying to Salvage It","meta":{"source":"The New York Times"},"_input_hash":1569967905,"_task_hash":554311543,"label":"artificial intelligence","_view_id":"classification","answer":"reject","_timestamp":1692283722,"_annotator_id":"textcat_news_headlines-bob","_session_id":"textcat_news_headlines-bob"}
{"text":"In Silicon Valley, a Voice of Caution Guides a High-Flying Uber","meta":{"source":"The New York Times"},"_input_hash":-1886037109,"_task_hash":-332936186,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283729,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
{"text":"How Silicon Valley Pushed Coding Into American Classrooms","meta":{"source":"The New York Times"},"_input_hash":1842734674,"_task_hash":-1664806480,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283729,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
{"text":"Silicon Valley Investors Flexed Their Muscles in Uber Fight","meta":{"source":"The New York Times"},"_input_hash":10406310,"_task_hash":58752667,"label":"artificial intelligence","_view_id":"classification","answer":"reject","_timestamp":1692283729,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
{"text":"Prodigy, for machine teaching. It's made by spaCy people. Another sentence, yo.","_input_hash":-1584346565,"_task_hash":-2142900962,"label":"artificial intelligence","_view_id":"classification","answer":"reject","_timestamp":1692283730,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
{"text":"Uber\u2019s Lesson: Silicon Valley\u2019s Start-Up Machine Needs Fixing","meta":{"source":"The New York Times"},"_input_hash":1886699658,"_task_hash":-234409469,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283730,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
{"text":"\u2018The Internet Is Broken\u2019: @ev Is Trying to Salvage It","meta":{"source":"The New York Times"},"_input_hash":1569967905,"_task_hash":554311543,"label":"artificial intelligence","_view_id":"classification","answer":"accept","_timestamp":1692283732,"_annotator_id":"textcat_news_headlines-claire","_session_id":"textcat_news_headlines-claire"}
To store this data in your own Prodigy database you can copy the data into a
file called ready-to-import.jsonl and then store it via the db-in
recipe.
Recipe command
prodigy db-in textcat_news_headlines ready-to-import.jsonl
Make sure to use the textcat_news_headlines dataset name if you want to follow
the next steps of this guide.
To review these annotations we can now point the review recipe to the
textcat_news_headlines dataset.
Recipe command
prodigy review textcat_reviewed textcat_news_headlines
When you run this recipe, you will see an annotation interface that looks like this:
Prodigy
The review recipe is able to gather all the information that it needs to
generate the review interface. It’s also very similar to the original interface
that the users saw, but the exception of the colored tags that show if the
annotator accepted or rejected the example. In this case, “bob” and “claire”
accepted while “alice” disagreed and rejected the example.
Other interfaces
The review interface will look differently depending on the original interface that was used. The aforementioned example used the binary classification interface but many other interfaces are supported as well.
Choice interface
Let’s assume that we re-used the textcat.manual recipe but now with
multiple labels.
Recipe command
PRODIGY_CONFIG_OVERRIDES='{"feed_overlap": true}' PRODIGY_ALLOWED_SESSIONS=alice,bob,claire prodigy textcat.manual textcat_choice ./news_headlines.jsonl --label "ai,policy,vc"
That means that the annotators will now see a non-binary choice menu rendered by
the choice interface, which the recipe uses under the hood.
Prodigy
When users annotate data using this interface, you’ll be able to run
review on these annotations too.
Recipe command
prodigy review textcat_choice_reviewed textcat_choice
And the review interface will now look something like this:
Prodigy
For each user you’ll still be able to see if they accepted, rejected or skipped. But you’ll also see which option each annotator selected. You’ll also notice that the option with the most agreed sessions is pre-selected automatically.
NER interface
Let’s now look at an example for reviewing for named entity recognition. Again,
you’ll need to start by running a recipe for your annotators. Let’s use
ner.manual.
Recipe command
PRODIGY_CONFIG_OVERRIDES='{"feed_overlap": true}' PRODIGY_ALLOWED_SESSIONS=alice,bob,claire prodigy ner.manual ner_headlines blank:en ./news_headlines.jsonl --label "COMPANY,PERSON"
This recipe will generate a ner_manual interface, which looks like
this:
Try it live and highlight entities!
When the annotations are done, you can run review on these annotations.
Recipe command
prodigy review textcat_reviewed textcat_news_headlines --label PERSON,COMPANY
This is what the review interface would now look like.
Prodigy
In this case we see that Bob didn’t recognise that “Apple” could also be interpreted as a company here.
Extra review settings.
Let’s say that you’re reviewing and that there are five annotators who all see the same example. Then, for a specific example, it could be that all five of those annotators agree on the annotation. You could argue that in these situations a review isn’t needed.
To make this easy, you can configure the review recipe to only automatically accept example where all annotators agree.
Recipe command
prodigy review textcat_reviewed textcat_news_headlines --label PERSON,COMPANY --auto_accept
This way, any example that appears in the stream where everyone agrees will be
automatically accepted on your behalf. By default, this mechanic is designed to
only auto accept examples where at least two annotators agreed. For more
information, be sure to check the review recipe docs.
Limitations
The review does it’s best to support a wide array of annotation
interfaces but there are a few annotation interfaces that aren’t supported.
In particular, the image_manual and audio_manual interfaces
aren’t supported because the very nature of the UI makes it hard to combine
annotations. These interfaces allow users to draw shapes and these may differ
due to small differences in pixel values. That doesn’t allow for a great review
experience which is why these aren’t supported.
Using models as “annotators” New: 1.13.1
As of v1.13.1 Prodigy added support for ner.model-annotate,
spans.model-annotate and textcat.model-annotate. These recipes
that can add annotations to a dataset from a model, as-if they were done by an
annotator. These recipes support any spaCy pipeline, which includes pipelines
that use large language models as a backend.
These “model as annotator”-recipes work great together with the review
recipe because they allow you to focus on examples where models disagree and
it’s these examples that might be interesting candidates to annotate first.
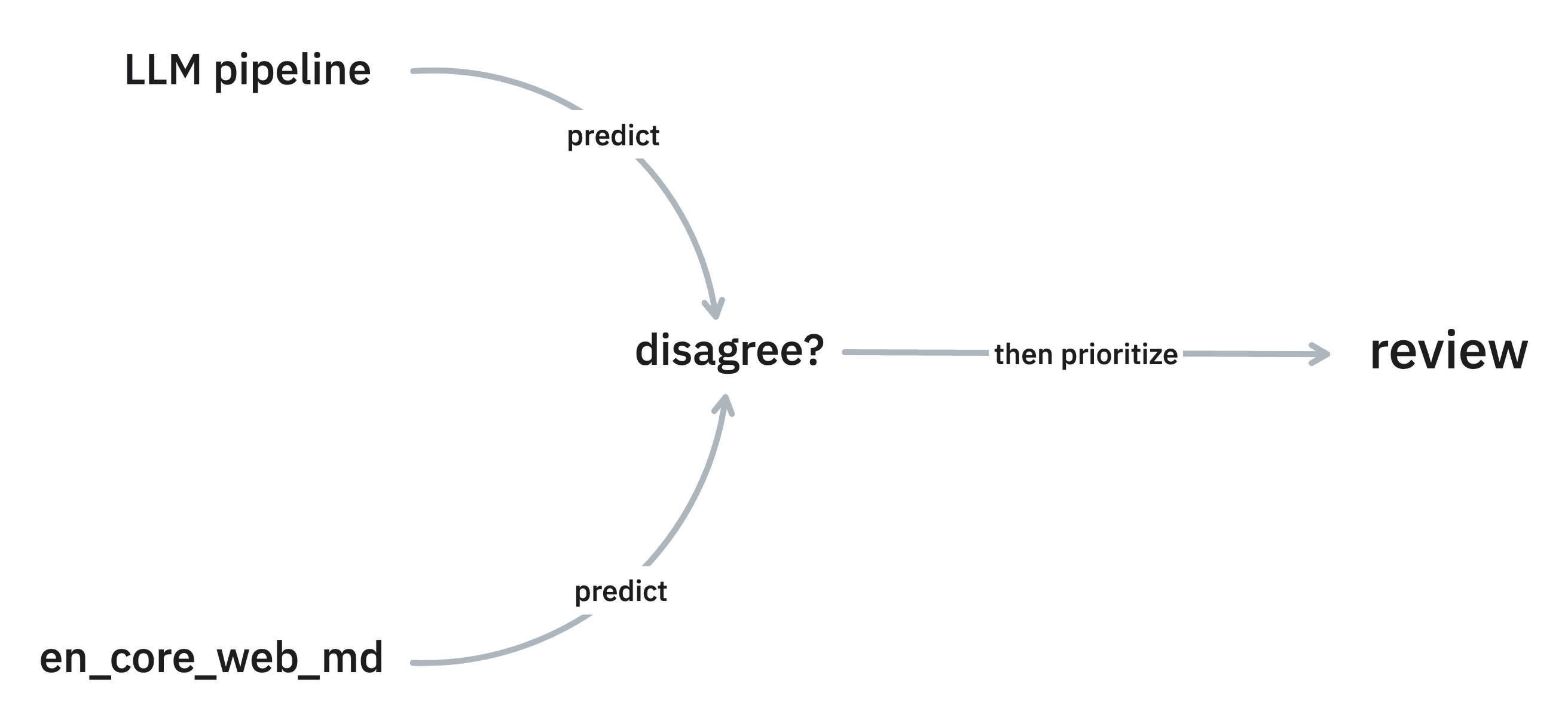
This technique is made especially useful with the introduction of large language models. These allow you to quickly prototype an NLP pipeline, which is great when you want to have a model aid you in annotating new data. If you can’t use a large lanugage model, there are many pre-trained alternatives, including the ones offered directly by spaCy. That means that, depending on your use case, you might be able to access more than one model to help you annotate. In particular, this allows you to leverage a new technique: leveraging their disagreement to prioritise examples.
The following will explore how to set up a “models as annotators” annotation
process for named entity recognition via the ner.model-annotate recipe.
Preparing two models
Let’s assume that we’re interested in a named entity use-case where we’d like to
detect “person” and “organisation” entities. For this use-case we can leverage
any of the pre-trained spaCy models, but we’ll use en_core_web_md in this
example.
First, you’ll need to make sure that this pipeline is downloaded.
Download the spaCy pipeline
python -m spacy download en_core_web_md
Next, we’ll also need some data to annotate. We’ll re-use the
news_headlines.jsonl dataset for this. You can download it via the link below.
Now that those are downloaded, we can use the spaCy pipeline to generate
annotations for the news_headlines.jsonl dataset.
Recipe command
prodigy ner.model-annotate ner_news_headlines en_core_web_md ./news_headlines.jsonl spacy_medium --labels PERSON,ORG
Getting labels from the 'ner' component Using 2 labels: ['PERSON', 'ORG'] 100%|████████████████████████████████████████████| 201/201 [00:00<00:00, 396.92it/s]
When you run this command, en_core_web_md will add annotations whenever a
PERSON or ORG entity is detected. Prodigy will also make sure that these
“annotations” appear as if they are made by an annotator named “spacy_medium”.
Let’s now repeat this by leveraging a spacy-llm model. That means that we’ll first need to set up a configuration file.
spacy-llm-demo.cfg: configuration file for spacy-llm[nlp]
lang = "en"
pipeline = ["llm"]
[components]
[components.llm]
factory = "llm"
save_io = true
[components.llm.task]
@llm_tasks = "spacy.NER.v2"
labels = ["PERSON", "ORG"]
[components.llm.task.label_definitions]
PERSON = "The name of a person. First name together with last name should result in single entity."
ORG = "The name of an organisation. This can be a business, NGO or government organisation."
[components.llm.model]
@llm_models = "spacy.GPT-3-5.v1"
config = {"temperature": 0.3}
[components.llm.task.examples]
@misc = "spacy.FewShotReader.v1"
path = "ner_examples.yml"
[components.llm.cache]
@llm_misc = "spacy.BatchCache.v1"
path = "local-ner-cache"
batch_size = 3
max_batches_in_mem = 10
This configuration file refers to an examples file, which contains examples like below.
ner_examples.yml- text: 'Steve Jobs was the famous CEO of Apple.'
entities:
PERSON: ['Steve Jobs']
ORG: ['Apple']
These configuration files can now be used to construct a local spaCy pipeline
that uses an LLM under the hood to perform the entity predictions. The following
command will do just that and save the pipeline in a folder name
en_ner_llm_demo.
Generate local spaCy model from spacy-llm config
dotenv run -- spacy assemble spacy-llm-demo.cfg en_ner_llm_demo
Now that we have a spaCy model defined locally we can run the same recipe as
before, but now we’ll point it to our LLM model. In order to that, you will have
to specify the --component setting manually. The aforementioned configuration
file adds a component called llm
Recipe command
dotenv run -- prodigy ner.model-annotate ner_news_headlines en_ner_llm_demo ./news_headlines.jsonl spacy_llm --labels PERSON,ORG --component llm
Getting labels from the 'llm' component Using 2 labels: ['PERSON', 'ORG'] 100%|████████████████████████████████████████████| 201/201 [03:11<00:00, 1.05it/s]
Reviewing model annotations
Now that two models ran against the dataset, we can point the review
recipe to the dataset with the model annotations.
Example
prodigy review ner_news_headlines_final ner_news_headlines --view-id ner_manual --label PERSON,ORG
From this review interface, you might see some examples where the models disagree. In this case, the models disagree but both models are also wrong.
But you may also find examples where they completely agree and they are both correct.
If you prefer, you can automatically accept all the examples where all the
models agree with each other by setting the --auto-accept flag. That way,
you’ll only be shown the examples where there is disagreement.
Example
prodigy review ner_news_headlines_final ner_news_headlines --view-id ner_manual --label PERSON,ORG --auto-accept
This example compares a spacy-llm model with a pretrained spaCy pipeline. Both
models are useful, but you may still want to iterate on both models before you
have them annotate large datasets. You may be able to improve the prompt, but
you may also find that the en_core_web_lg model works a little bit better. It
may also be beneficial to add your own trained pipeline into the mix, or another
custom pipeline that relies on pattern files.
Finally, and as mentioned before, the exact same process can also be used for
text classification, via textcat.model-annotate and span categorisation
spans.model-annotate.
More inspiration
The previous example compares the predictions from a pretrained spaCy model with the predictions from a large language model. While this approach is relatively general, it does help to emphasize that there are many other modelling options as well.
-
You could leverage rule-based matching to create a spaCy model. This can be a great option when you have some knowledge upfront on what texts you’d like to detect.
-
You could leverage a model that you’ve trained yourself via the
trainrecipe. -
You could choose to leverage pretrained models from the spaCy universe or Huggingface.