Task Routing
Prodigy allows you to distribute the annotation workload among multiple annotators or workers. You can make sure examples are seen by multiple annotators or even set up custom routing so that specific examples get seen by specific annotators.
Quickstart
In the prodigy.json configuration file you can specify the overlap with the
feed_overlap parameter. By default, it is set to false, indicating that
there should be no overlap between the annotators. Each example will be seen by
exactly one person.
You can read more about the prodigy.json file in the
configuration guide.
In the prodigy.json configuration file you can specify the overlap with the
feed_overlap parameter. By setting it to true, you can specify that each
example should be seen by each annotator.
You can read more about the prodigy.json file in the
configuration guide.
In the prodigy.json configuration file you can specify partial overlap with
the annotations_per_task parameter. Please note that this setting is
contradictory to "feed_overlap": true, which is why setting both will result
in the config validation error. By setting it to an integer or whole number
float, you can specify the number of annotators that should see each example. So
in the case of "annotations_per_task": 2 or "annotations_per_task": 2.0,
you’ll have two people annotate each example and in the case of
"annotatations_per_task": 3 you’ll have three.
If you want to make sure that you get exactly two annotators on each example
then you should also configure the session names upfront via the
PRODIGY_ALLOWED_SESSIONS environment variable. Otherwise, Prodigy may not be
aware of all the sessions when the server starts. You can learn more about the
details of this mechanic in the
section on session creation below.
You can read more about the prodigy.json file in the
configuration guide.
In the prodigy.json configuration file you can specify partial overlap with
the annotations_per_task parameter. Please note that this setting is
contradictory to "feed_overlap": true, which is why setting both will result
in the config validation error. By setting it to a decimal, you can specify the
number of annotations that each example should receive on average. So in the
case of "annotations_per_task": 1.5, each example should receive 1.5
annotations from randomly selected annotators.
The annotator assignment is handled by re-using the task hash of each example which ensures a consistent allocation within a pool of annotators. If you’re curious about the details on how this assignment works, check the section on routing below.
You can read more about the prodigy.json file in the
configuration guide.
You can write custom task routers in Python that allow you to fully customise how each example is sent to an annotator. This will allow you to do things like:
- Route text examples based on the language in the text.
- Send medical image examples to the appropriate expert.
- Have everyone annotate an example where the model has low confidence.
- Have more people annotate an example based on a predefined metric of priority.
As long as you can express your needs in Python function, you’ll be able to route the examples as your use-case requires. To learn more, check the section on custom task routers below.
What is task routing?
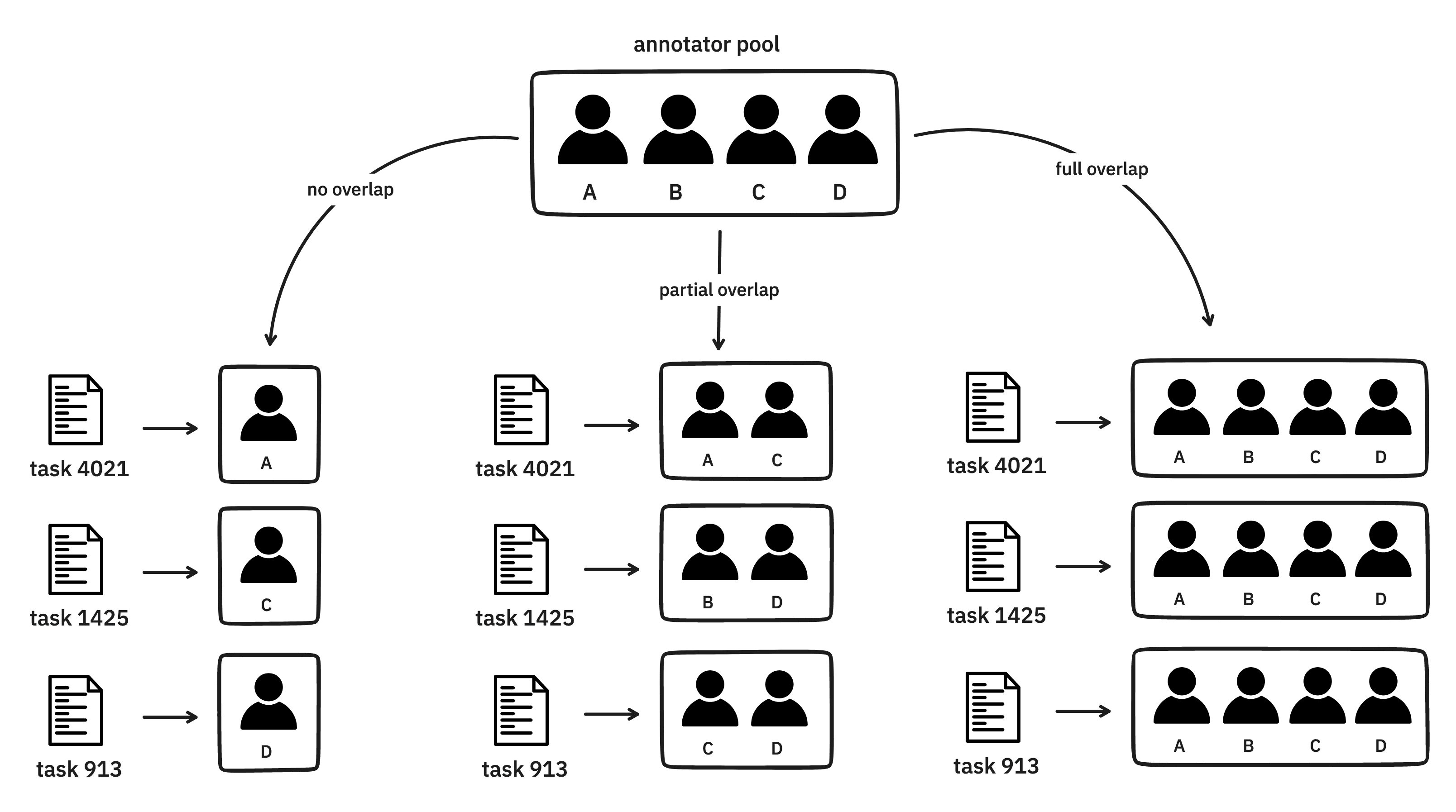
Given a pool of annotators and a set an examples to annotate, there are many ways to distribute the workload.
The way tasks are routed to annotators can be fully customised with Python code,
but you can also configure common routing practices via "feed_overlap" or
"annotations_per_task" setting in
the Prodigy configuration file. The different
configurations are listed below.
-
No overlap: if you want zero overlap between the annotators then you may set
"feed_overlap": false. This setting will ensure that you get the most annotations given your annotator pool and the project duration, but you won’t be able to confirm annotator agreement because none of the annotators will overlap. -
Full overlap: if you want full overlap between the annotators then you may set
"feed_overlap": true. This setting will allow you to confirm annotator agreement because each example should be seen by every annotator. However, as a consequence, you may end up with fewer total examples annotated compared tono overlapsetting (assuming the same annotator pool and project duration). -
Partial overlap: if you want each example to be seen by
nannotators on average then you may set"annotations_per_task": n. For example, if you want each example to be seen by three annotators, then you can configure"annotations_per_task": 3. Or if you want each example to receive 2.5 annotations on average, then you’d set"annotations_per_task": 2.5
You don’t need to stick to a single routing setting in your project. It can be perfectly sensible to allow for more annotator overlap early on in the project because the annotator agreement can help you improve your annotation process. Later, after you’re confident that the annotation guidelines are properly in place, you may choose to overlap less and get more annotations instead.
Video tutorial: task router deep dive.
The following video does a deep dive into task routers by going through multiple custom implementations of task routers by hand. If you’re eager to know more about the implementation details it can be a great starting point.
How does task routing work in Prodigy?
To understand the details of task routing in Prodigy, it helps to revisit how sessions are created first.
Session creation
When Prodigy is running with overlap allowed, you should set a session name in
the URL so that your name is attached to the annotation you provide. When
Prodigy sees a request come in with a session name attached, Prodigy creates a
session for each user. For example, ?session=joe would create a session that
is unique to the current dataset and the username "joe".

This means that sessions are dynamic. Users can join at any time and their
sessions will stay around until Prodigy restarts. It also means that Prodigy is
unaware of a user unless they visit the URL with their session. If you want
Prodigy to create sessions for all the users upfront you will need to pass the
user names via the PRODIGY_ALLOWED_SESSIONS
environment variable when starting
Prodigy. If you do this, however, you must restart the Prodigy server when you
want to add users that weren’t passed in via the environment variable.

It’s important to understand how sessions are created in Prodigy because they need to be available if we want to assign tasks to them.
Routing via Python functions
Let’s now consider how a task might get routed to a session.
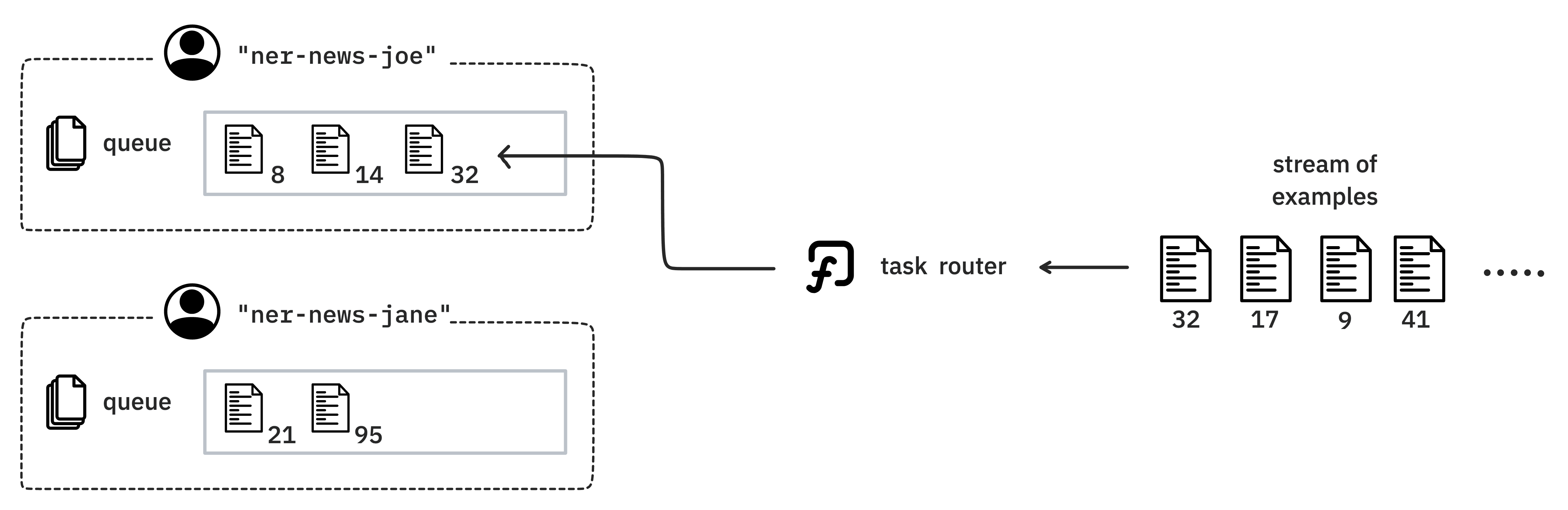
In Prodigy a task router is a Python function that outputs a list of session
names to route the example to. A task router has access to the
Controller state, the session_id that is
currently asking for more exampels and the dictionary that describes the example
from the stream.
You can write your own task routers, but you need make sure that the function is consistent. To help explain what we mean with this, let’s consider an implementation. Suppose that we’re interested in creating a function that can route each example to a random annotator from the session pool. Would the following snippet of code work?
A random task routerimport random
def task_router_conf(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
# Get a list of available session id's from the Controller
pool_of_annotators = ctrl.session_ids
# Return a list with a single random candidate
return [random.choice(pool_of_annotators)]
This task router picks an annotator randomly from the pool of session ids that’s
currently available. While this does select an annotator for the current run, it
won’t be a consistent mapping from task to annotator because users may join at
any moment. It even may re-route the same example to multiple users if the
Prodigy server restarts and the available sessions reset. Even if you would
provide sessions upfront via the PRODIGY_ALLOWED_SESSIONS environment
variable, it could result in duplicates because random.choice will just try to
pick a random annotator every time.
Instead of using a random module, we might be better off using task hashes. Prodigy has a hashing mechanic, described here, that adds unique identifiers to each annotation example. These hashes are used to deduplicate the examples but they can also be used to route examples to annotators.
Let’s rewrite the function to use these hashes instead.
A random task router that uses hashesdef task_router_conf(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
# Get a list of available session id's from the Controller
pool_of_annotators = ctrl.session_ids
# Get the task hash from the current example
task_hash = item['_task_hash']
# Get a "random" but deterministic index by the modulo operator
idx = task_hash % len(pool_of_annotators)
# Use idx to return a list with a single "random" annotator
return [pool_of_annotators[idx]]
This way, if the sessions are known upfront, you’ll be able to maintain a consistent mapping from task to annotator. That said, if you allow for new users to join at any time then even this mechanic may not be able to prevent duplicates perfectly. If we really want to prevent duplicates, we’ll need to check the state in the database.
A random task router that uses hashes and checks the databasedef task_router_conf(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
# Get the task hash from the current example
task_hash = item['_task_hash']
# Count how often the current task hash appears in the dataset
hash_count = ctrl.db.get_hash_count(ctrl.dataset, session_id, kind="task")
# Returning an empty list will not route this example to anyone
if hash_count >= 1:
return []
# Get a list of available session id's from the Controller
pool_of_annotators = ctrl.session_ids
# Get a "random" but deterministic index by the modulo operator
idx = task_hash % len(pool_of_annotators)
# Use idx to return a list with a single "random" annotator
return [pool_of_annotators[idx]]
This task router will make more requests to the database, but it really puts up a hard constraint: it will not route any examples if it yields a duplicate.
Weather or not such a constraint is pragmatic depends a lot on your use-case. If
you consistently work with the same set of annotators and if you predefine your
PRODIGY_ALLOWED_SESSIONS variable upfront then it will be unlikely to be a big
concern. But if you are annotating in a very dynamic environment with annotators
joining frequently and the server restarting often too then you may consider
putting such measures in your custom function.
Configuring custom task routers
If you have written a custom task router and you’d like to use it in a custom
recipe then you can add it as a callback by
passing it as a value for the "task_router" key in the dictionary output of
your recipe function.
recipe.py (except)pseudocode import prodigy
def custom_task_router(ctrl, session_id, item):
...
@prodigy.recipe(
"my-custom-recipe",
dataset=("Dataset to save answers to", "positional", None, str),
view_id=("Annotation interface", "option", "v", str)
)
def my_custom_recipe(dataset, view_id="text"):
# Load your own streams from anywhere you want
stream = load_my_custom_stream()
return {
"dataset": dataset,
"view_id": view_id,
"stream": stream,
"task_router": custom_task_router
}
Custom Routing Examples
To help you implement your own custom routers, we’ll show a few example implementations below.
Example 1: selecting n annotators
The following task router will select n random annotators from the pool via
the hashing trick we mentioned earlier. Note that this task router is
available directly from the Prodigy library
via the task routers submodule.
def task_router_n(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
# Define how many annotators need to see each example.
N_ANNOT = 2
# Count how often the current task hash appears in the dataset, maybe skip
hash_count = ctrl.db.get_hash_count(ctrl.dataset, session_id, kind="task")
if hash_count >= N_ANNOT:
return []
# Fetch all available ids to pick from
pool = ctrl.session_ids
# Again use the hashing trick, but now keep pulling until `N_ANNOT` is reached
h = item[TASK_HASH_ATTR]
idx = h % len(pool)
annot = [pool.pop(idx)]
while len(annot) < N_ANNOT:
# If the pool is empty, just return the annotators sofar
if len(pool) == 0:
return annot
idx = h % len(pool)
annot.append(pool.pop(idx))
return annot
Just like the example before, if there are already two annotations for the current example in the dataset then this task will not be routed to anyone anymore.
Example 2: model confidence
Let’s say that you want to assign more annotators when a machine learning model gives it a low confidence. A low confidence might indicate that it is a harder example which is why you’d want more annotators to agree before using it to train a model. Then you might consider implementing a task router like this one:
Task router based on model confidencepseudocode def task_router_conf(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
"""Route tasks based on the confidence of a model."""
# Get all sessions known to the Controller now
all_annotators = ctrl.session_ids
# Calculate a confidence score from a custom model
confidence_score = model(item['text'])
# If the confidence is low, the example might be hard
# and then everyone needs to check
if confidence_score < 0.3:
return all_annotators
# Otherwise just one person needs to check.
# We re-use the task_hash to ensure consistent routing of the task.
idx = item['_task_hash'] % len(all_annotators)
# Return list with a single annotator reference
return [all_annotators[idx]]
Example 3: Languages
The final example shows how you might route examples based on the language of
the task. This example assumes that a language key is available on each
example in the stream.
def task_router_lang(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
"""Route tasks based on the language property of the item."""
# Select based on language
if item['language'] == 'Dutch':
return [ctrl.get_session_name('vincent')]
if item['language'] == 'German':
return [ctrl.get_session_name('ines')]
if item['language'] == 'Australian':
return [ctrl.get_session_name('matt')]
# All other scenarios: who comes first
return [session_id]
This example uses the Controller.get_session_name method to turn a
human-readable name into it’s appropriate session name. In Prodigy a session
name will also contain a prefix for the dataset that the annotations are saved
into, and the .get_session_name method ensures the right string.
Note that this example assumes that "vincent", "matt" and "ines" are
available upfront via the PRODIGY_ALLOWED_SESSIONS environment variable
because the session needs to exist before a task can be routed to it. If
you’re dealing with a scenario where these sessions may need to be generated on
the fly then you’ll want an implementation like this:
def get_name_and_confirm(ctrl: Controller, name: str):
sess_name = ctrl.get_session_name(name)
ctrl.confirm_session(sess_name)
return sess_name
def task_router_lang(ctrl: Controller, session_id: str, item: Dict) -> List[str]:
"""Route tasks based on the language property of the item."""
# Select based on language
if item['language'] == 'Dutch':
return [get_name_and_confirm('vincent')]
if item['language'] == 'German':
return [get_name_and_confirm('ines')]
if item['language'] == 'Australian':
return [get_name_and_confirm('matt')]
# All other scenarios: who comes first
return [session_id]
This way, the task router makes sure that the appropriate session exists before tasks are queued up.
Work stealing
Besides task routing, Prodigy also offers a work stealing mechanic that might also influence who will annotate the examples. Work stealing occurs whenever an annotator has an empty queue and can use the queue of another user to keep annotating.
Work stealing is a preventive mechanism to avoid the loss of records in a stream. There might be a situation where an annotator requests a batch of examples for annotation, effectively locking those examples, but never actually annotates them. Work stealing enables annotators who reach the end of a shared stream to annotate these locked examples.
As an example, it’s possible that annotator A has an empty queue after annotating for an hour while annotator B started a session and stopped annotating with some items left in the queue. In this situation, Prodigy can “steal work” from the stale annotator B and pass the work to annotator A.
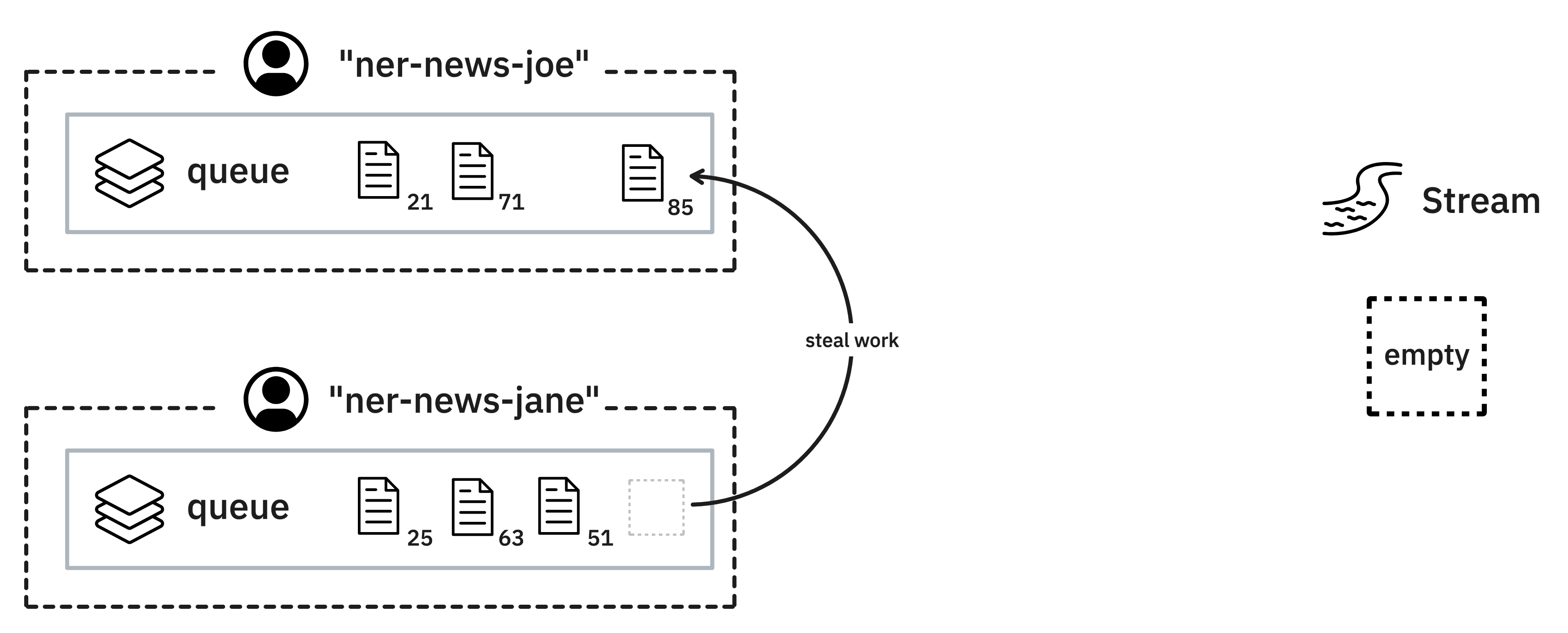
This mechanic can be very useful, but there may also be moments where you don’t want work stealing to happen. In particular, work stealing might cause a single fast user to annotate more examples than average, which could cause an annotator imbalance. It might also cause examples to be annotated by a user, even if the task router wouldn’t make the assignment.
Work stealing is turned on by default but there is an allow_work_stealing
setting available in the prodigy.json configuration file
that allows you to turn work stealing off.