


Documentation
- Downloadable developer tool and library
- Create, review and train from your annotations
- Runs entirely on your own machines
- Powerful built-in workflows
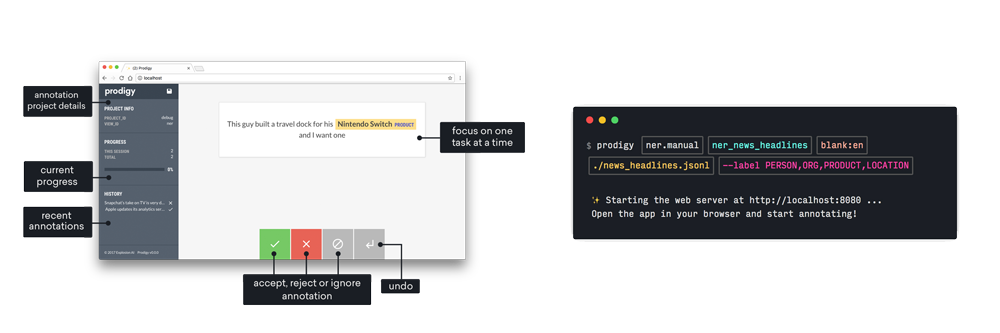
Prodigy’s browser-based annotation app has been carefully designed to be as efficient as possible, making it easy to include your domain experts in the data collection process and transfer their knowledge into your AI systems.
Prodigy lets you keep your data private and fully under your control. It’s provided as a standalone piece of software that doesn’t depend on any external services. All models and other assets you create are 100% yours, and you can export the data in standard formats so there's no lock-in.
