

Documentation
- Downloadable developer tool and library
- Create, review and train from your annotations
- Runs entirely on your own machines
- Powerful built-in workflows

Prodigy is one of the go-to data development and annotation tools in academia, used by researchers at hundreds of universities and research institutions who have published their results and datasets at NeurIPS, ACL and EMNLP, and in journals covering fields like medicine, bioinformatics and digital humanities.

This case study shows how the Data Science team at Nesta, the UK’s innovation agency for social good, built an NLP pipeline using spaCy and Prodigy to extract skills from 7 million online job ads to better understand UK skill demand. Core to the pipeline is a custom mapping step, that allows users to match extracted skills to any government standard taxonomy.
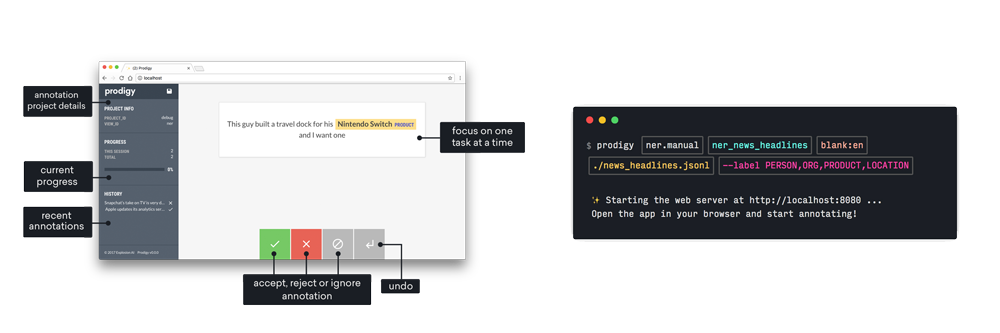
Prodigy’s browser-based annotation app has been carefully designed to be as efficient as possible, making it easy to include your whole team in the data collection process and transfer their knowledge into your AI systems.
We’re always happy to support research projects and researchers at degree-granting academic institutions can apply for an interim license to use Prodigy for free. To claim your research license, email us and include your university details.
To cite Prodigy in your work, you can use the following citation and add an optional version for a specific version of Prodigy. If you’ve published a paper that uses Prodigy, we’d love to check it out – feel free to email us!
