

Documentation
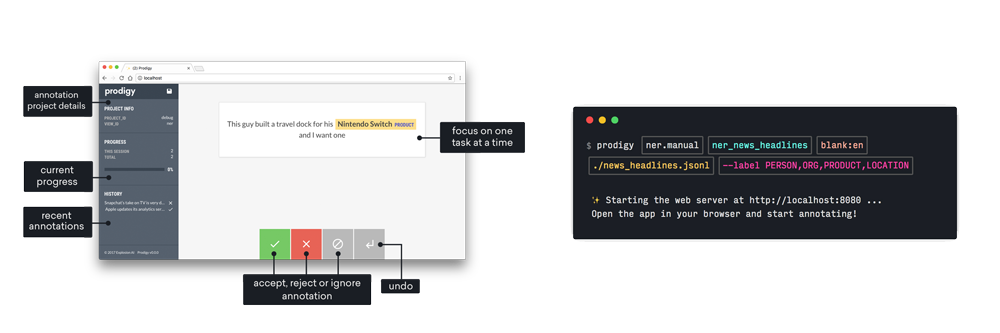
- Downloadable developer tool and library
- Create, review and train from your annotations
- Runs entirely on your own machines
- Powerful built-in workflows
Prodigy makes expert workflows and the latest best practices available to everyone. Build transparent AI systems by distilling domain-specific knowledge from larger models and human experts into fully private pipelines that you can run cheaply and efficiently in-house.
Prodigy runs entirely under your control, making it suitable for even the strictest privacy requirements. You can download it and run it locally right out of the box, or adapt it to serve your infrastructure needs. The models you produce are yours as well, with absolutely no lock-in.
