Installation & Setup
Installation
Prodigy supports macOS, Linux and Windows and can be installed on Python 3.8 and above. After ordering Prodigy, you should receive an email confirmation that includes your license key(s) and a download link for all available platform-specific wheels. Whenever a new version of Prodigy is released, you’ll be able to download it using the same link. It’s recommended to use a new virtual environment for installing Prodigy.
Install Prodigy via pip
As of v1.11, you can now download and install Prodigy via pip by pointing it
to our download server and authenticating with your license key. You can
find your license key in the original email confirmation you received when you
first ordered Prodigy. (Can’t find it anymore?
Use this form
to re-send your order email, or
email us
with as many details as possible about your order so we can track it down for
you!)
If you want to install the latest pre-release version of Prodigy to try out
the forthcoming features, run pip with the --pre flag:
To upgrade to the lastest stable release, use the --upgrade flag:
Installing via pip also gives you access to older versions, in case you ever
need to switch between them. You can specify the version number just like you
would for any other Python package, e.g. prodigy==1.11.0. You can also open
the index URL in your browser to see all available wheels. You’ll be able to
download from our pip server for as long as the upgrades included with your
Prodigy order are active. If your upgrades have expired, you can still keep
using Prodigy. We recommend downloading the wheel files as a back-up, just in
case – they’re all yours!
Adding Prodigy to your requirements.txt New: 1.11.1
The Prodigy download server also exposes a package index endpoint via
download.prodi.gy/index that you can use with --extra-index-url. This lets
you include Prodigy in your requirements.txt by adding a line at the top of
the file:
requirements.txt
To install this the pre-release versions with this requirements file you’ll want to run it via:
Install Prodigy from a wheel file
Wheel installers are basically pre-compiled Python package installers. You can
install them like any other Python package by pointing pip install at the
local path of a .whl file you downloaded.
If you’re unsure about which file to use, you can also point pip to a directory of wheels using the -f option and it will automatically pick the latest and best-matching wheel:
About the 'is not a supported wheel on this platform' error
Double-check that you’ve downloaded the correct wheel and make sure your version
of pip is up to date. If it still doesn’t work, check if the file name matches
your platform (distutils.util.get_platform()) and rename the file if
necessary. Here’s how to interpret the file names in Prodigy v1.15 or lower:
python -m pipinstallprodigy-1.11.0-cp38-cp38m-macosx_10_14_x86_64.whlFor more details, see
this article on Python wheels.
Essentially, Python wheels are only archives containing the source files –
so you can also just unpack the wheel and place the contained prodigy
package in your site-packages directory.
Making the 'prodigy' CLI command work
On installation, Prodigy will set up the alias commands prodigy and pgy.
This should work fine and out-of-the-box on most macOS and Linux setups. If not,
you can always run the commands by prefixing them with python -m, for example:
python -m prodigy stats. Alternatively, you can create your own alias, and
add it to your .bashrc
to make it permanent:
alias prodigy="python -m prodigy"On Windows you can also create a Windows activation script as a .ps1 file and
run it in your environment, or add it to your PowerShell profile. See
this thread for more details.
Function global:pdgy { python -m prodigy $args}Function global:prodigy { python -m prodigy $args}Function global:spacy { python -m spacy $args}Using Prodigy with Docker
By default, Prodigy starts the web server on localhost and port 8080. If
you’re running Prodigy via a Docker container or a
similar containerized environment, you’ll have to set the host to 0.0.0.0.
Simply edit your prodigy.json and add the following:
{ "host": "0.0.0.0"}See this thread for more details and background. The above approach should also work in other environments if you come across the following error on startup:
OSError: [Errno 99] Cannot assign requested addressUsing and installing spaCy pipelines
To use Prodigy’s built-in recipes for components like NER or text
classification, you typically also want to install a spaCy pipeline – for
example, the
small English pipeline,
en_core_web_sm. Note that the latest version of Prodigy requires
spaCy v3.1 or above.
python -m spacy download en_core_web_smIf you have trained your own spaCy pipelines, you can load them into Prodigy
using the path to the model directory. You can also use the
spacy package command to turn it into a
Python package, and install it in your current environment. All Prodigy recipes
that allow a spacy_model argument can either take the name of an installed
package, or the path to a valid model directory. Keep in mind that a new
minor version of spaCy also means that you should retrain your models. For
example, models trained with spaCy v3.1 may not not be 100% compatible with
v3.2.
Using Prodigy with JupyterLab
If you’re using JupyterLab, you can install our
jupyterlab-prodigy extension.
It lets you execute recipe commands in notebook cells and opens the annotation
UI in a JupyterLab tab so you don’t need to leave your notebook to annotate
data.
python -m pip install jupyterlab-prodigyConfiguration
When you first run Prodigy, it will create a folder .prodigy in your home
directory. By default, this will be the location where Prodigy looks for its
configuration file, prodigy.json. You can change this directory via the
environment variable PRODIGY_HOME, or provide a path to a
custom JSON file via PRODIGY_CONFIG (as of v1.11).
When you run Prodigy, it will first check if a global configuration file
exists. It will also check the current working directory for a
prodigy.json or .prodigy.json. This allows you to overwrite specific
settings on a project-by-project basis. As of v1.11, you can also provide
config overrides on the CLI. The following settings can be
defined in your config file, or in the "config" returned by a recipe.
prodigy.json
| Setting | Description | Default |
|---|---|---|
theme | Name of UI theme to use. | "basic" |
custom_theme | Custom UI theme overrides, keyed by name. | {} |
buttons | New: 1.10 Buttons to show at the bottom of the screen in order. If an answer button is disabled, the user will be unable to submit this answer and the keyboard shortcut will be disabled as well. Only the "undo" action will stay available via keyboard shortcut or click on the sidebar history. | ["accept", "reject", "ignore", "undo"] |
batch_size | Number of tasks to return to and receive back from the web app at once. A low batch size means more frequent updates. | 10 |
history_size | New: 1.10 Maximum number of examples to show in the sidebar history. Defaults to the value of batch_size. Note that the history size can’t be larger than the batch size. | 10 |
port | Port to use for serving the web application. Can be overwritten by the PRODIGY_PORT environment variable. | 8080 |
host | Host to use for serving the web application. Can be overwritten by the PRODIGY_HOST environment variable. | "localhost" |
cors | Enable or disable cross-origin resource sharing (CORS) to allow the REST API to receive requests from other domains. | true |
db | Name of database to use. | "sqlite" |
db_settings | Additional settings for the respective databases. | {} |
validate | Validate incoming tasks and raise an error with more details if the format is incorrect. | true |
auto_exclude_current | Automatically exclude examples already present in current dataset. | true |
instant_submit | Instantly submit a task after it’s answered in the app, skipping the history and immediately triggering the update callback if available. | false |
feed_overlap | Whether to send out each example once so it’s annotated by someone (false) or whether to send out each example to every session (true). Should be used with custom user sessions set via the app (via /?session=user_name). Setting feed_overlap to true and annotations_per_task will result in a config validation error as they are contradictory. | false |
annotations_per_task | New: 1.12 Configure partial overlap by specifying the average number of expected annotations per task. Setting feed_overlap to true and annotations_per_task will result in a config validation error as they are contradictory. Should be used with custom user sessions set via the app (via /?session=user_name). | null |
allow_work_stealing | New: 1.12 Whether it should be possible for a session that has run out of tasks to queue up tasks from other (possibly idle) sessions. This setting makes sure that all tasks are annotated as soon as possible at the cost of potentially introducing some duplicates in the final dataset. | true |
total_examples_target | New: 1.11 Total number of examples that should be annotated to reach a progress of 100%. Useful for infinite streams or if completion doesn’t map to stream size. If 0, the target will be read from stream if possible. | 0 |
ui_lang | New: 1.10 Language of descriptions, messages and tooltips in the UI. See here for available translations. | "en" |
ui_lang_locale | New: 1.18 Overrides for individual descriptions, messages and tooltips in the UI. See here for available options. | {} |
project_info | New: 1.10 Project info shown in sidebar, if available. The list of string IDs can be modified to hide or re-order the items. | ["dataset", "session", "lang", "recipe_name", "view_id", "label"] |
show_stats | Show additional stats, like annotation decision counts, in the sidebar. | true |
hide_meta | Hide the meta information displayed on annotation cards. | false |
show_flag | Show a flag icon in the top right corner that lets you bookmark a task for later. Will add "flagged": true to the task. | false |
instructions | Path to a text file with instructions for the annotator (HTML allowed). Will be displayed as a help modal in the UI. | false |
swipe | Enable swipe gestures on touch devices (left for accept, right for reject). | false |
swipe_gestures | New: 1.10.5 Mapping of swipe gestures left and right to annotation decisions. | { "left": "accept", "right": "reject" } |
split_sents_threshold | Minimum character length of a text to be split by the split_sentences preprocessor, mostly used in NER recipes. If false, all multi-sentence texts will be split. | false |
html_template | Optional Mustache template for content in the html annotation interface. All task properties are available as variables. | false |
global_css | CSS overrides added to the global scope. Takes a string value of the CSS code. | null |
global_css_urls | New: 1.14.5 List of remote CSS files to load. You can use this to add your favorite CSS library for building a custom HTML interface | null |
global_css_dir | New: 1.14.5 Directory of CSS files to mount to the Prodigy app. Files are added to the global CSS scope. | null |
javascript | Custom JavaScript added to the global scope. Takes a string value of the JavaScript code. | null |
javascript_urls | New: 1.14.5 List of remote JavaScript files to load into the Prodigy app. | null |
javascript_dir | New: 1.14.5 Local directory with JavaScript files to load for your custom interface. | null |
writing_dir | Writing direction. Mostly important for manual text annotation interfaces. | ltr |
show_whitespace | Always render whitespace characters as symbols in non-manual interfaces. | false |
exclude_by | New: 1.9 Which hash to use ("task" or "input") to determine whether two examples are the same and an incoming example should be excluded if it’s already in the dataset. Typically used in recipes. | "task" |
Overriding config settings New: 1.11
By default, Prodigy will look for a prodigy.json in your user home directory
(set by the PRODIGY_HOME environment variable). You can also
provide a custom path to a JSON file to use instead by setting the
PRODIGY_CONFIG variable:
export PRODIGY_CONFIG="/path/to/prodigy.json"During development, it can often be useful to quickly overwrite certain config
settings, without having to edit your prodigy.json. The
PRODIGY_CONFIG_OVERRIDES environment variable lets you provide a dictionary of
config settings that overrides anything in your global, local or recipe-specific
settings. Make sure that the dictionary provide is valid JSON and uses
double quotes:
export PRODIGY_CONFIG_OVERRIDES='{"batch_size": 20}'If you enable basic or verbose logging, e.g. by setting
PRODIGY_LOGGING=basic, Prodigy will show you where your config settings are
coming from, which can be very helpful for debugging.
Database setup
By default, Prodigy uses SQLite to store annotations in a simple database file in your Prodigy home directory. If you want to use the default database with its default settings, no further configuration is required and you can start using Prodigy straight away. Alternatively, you can choose to use Prodigy with a MySQL or PostgreSQL database, or write your own custom recipe to plug in any other storage solution. For more details, see the database API documentation.
prodigy.json
| Database | ID | Settings |
|---|---|---|
| SQLite | sqlite | name for database file name (defaults to "prodigy.db"), path for custom path (defaults to Prodigy home directory), plus sqlite3 connection parameters. To only store the database in memory, use ":memory:" as the database name. |
| MySQL | mysql | MySQLdb or PyMySQL connection parameters. |
| PostgreSQL | postgresql | psycopg2 connection parameters. Can also be set via environment variables. |
Environment variables
Prodigy lets you set the following environment variables:
| Variable | Description |
|---|---|
PRODIGY_HOME | Custom path for the Prodigy home directory. Defaults to the equivalent of ~/.prodigy. |
PRODIGY_CONFIG | New: 1.11 Custom path to JSON file to read the global Prodigy config from. |
PRODIGY_CONFIG_OVERRIDES | New: 1.11 JSON object with overrides to apply to config, e.g. '{"batch_size": 20}'. |
PRODIGY_LOGGING | Enable logging. Values can be either basic (simple logging) or verbose (more details per entry). |
PRODIGY_LOG_LOCALS | New: 1.12 Also log local variables when Prodigy calls sys.exit due to an error. Value can be 1. |
PRODIGY_PORT | Overwrite the port used to serve the Prodigy app and REST API. Supersedes the settings in the global, local and recipe-specific config. |
PRODIGY_HOST | Overwrite the host used to serve the Prodigy app and REST API. Supersedes the settings in the global, local and recipe-specific config. |
PRODIGY_ALLOWED_SESSIONS | Define comma-separated string names of multi-user session names that are allowed in the app. |
PRODIGY_BASIC_AUTH_USER | Add super basic authentication to the app. String user name to accept. |
PRODIGY_BASIC_AUTH_PASS | Add super basic authentication to the app. String password to accept. |
Data validation
Wherever possible, Prodigy will try to validate the data passed around the
application to make sure it has the correct format. This prevents confusing
errors and problems later on – for example, if you use a string instead of a
number for a config argument, or try to train a text classifier on an NER
dataset by mistake. To disable validation you can set "validate": False in
your prodigy.json or recipe config.
| Stream | Validate each incoming task in the stream for the given annotation interface. |
| Prodigy config | New: 1.9 Validate the global, local and recipe config settings on startup. |
| Recipe | New: 1.9 Validate the dictionary of components returned by a recipe. |
| Training examples | New: 1.9 Validate training examples for the given component in train, train-curve and data-to-spacy. |
Debugging and logging
If Prodigy raises an error, or you come across unexpected results, it’s often
helpful to run the debugging mode to keep track of what’s happening, and how
your data flows through the application. Prodigy uses the
logging module to provide
logging information across the different components. The logging mode can be set
as the environment variable PRODIGY_LOGGING. Both logging modes log the same
events, but differ in the verbosity of the output.
| Logging mode | Description |
|---|---|
basic | Only log timestamp and event description with most important data. |
verbose | Also log additional information, like annotation data and function arguments, if available. |
Example output of PRODIGY_LOGGING=basic
$ PRODIGY_LOGGING=basic prodigy ner.teach test en_core_web_sm "rats" --api guardian
13:11:39 - DB: Connecting to database 'sqlite'13:11:40 - RECIPE: Calling recipe 'ner.teach'13:11:40 - RECIPE: Starting recipe ner.teach13:11:40 - LOADER: Loading stream from API 'guardian'13:11:40 - LOADER: Using API 'guardian' with query 'rats'13:11:42 - MODEL: Added sentence boundary detector to model pipeline13:11:43 - RECIPE: Initialised EntityRecognizer with model en_core_web_sm13:11:43 - SORTER: Resort stream to prefer uncertain examples (bias 0.8)13:11:43 - PREPROCESS: Splitting sentences13:11:44 - MODEL: Predicting spans for batch (batch size 64)13:11:44 - Model: Sorting batch by entity type (batch size 32)13:11:44 - CONTROLLER: Initialising from recipe13:11:44 - DB: Loading dataset 'test' (168 examples)13:11:44 - DB: Creating dataset '2017-11-20_13-07-44'
✨ Starting the web server at http://localhost:8080 ... Open the app in your browser and start annotating!
13:11:59 - GET: /project13:11:59 - GET: /get_questions13:11:59 - CONTROLLER: Iterating over stream13:11:59 - Model: Sorting batch by entity type (batch size 32)13:11:59 - CONTROLLER: Returning a batch of tasks from the queue13:11:59 - RESPONSE: /get_questions (10 examples)13:12:07 - GET: /get_questions13:12:07 - CONTROLLER: Returning a batch of tasks from the queue13:12:07 - RESPONSE: /get_questions (10 examples)13:12:07 - POST: /give_answers (received 7)13:12:07 - CONTROLLER: Receiving 7 answers13:12:07 - MODEL: Updating with 7 examples13:12:08 - MODEL: Updated model (loss 0.0172)13:12:08 - PROGRESS: Estimating progress of 0.090913:12:08 - DB: Getting dataset 'test'13:12:08 - DB: Getting dataset '2017-11-20_13-07-44'13:12:08 - DB: Added 7 examples to 2 datasets13:12:08 - CONTROLLER: Added 7 answers to dataset 'test' in database SQLite13:12:08 - RESPONSE: /give_answers13:12:11 - DB: Saving database
Saved 7 annotations to database SQLiteDataset: testSession ID: 2017-11-20_13-07-44Tracebacks and Local Variables New: 1.12
Sometimes Prodigy will recognize an error and exit the program with a helpful
message. At times though, when you’re debugging, you’ll be interested in seeing
the full Python traceback instead. If you have PRODIGY_LOGGING="basic"
configured then you’ll get a traceback whenever Prodigy throws such a message.
If you want to dive even deeper, you can also see the Python variables in the
local scope at the time of the error message by passing PRODIGY_LOG_LOCALS=1
on the terminal.
Example output of traceback
> PRODIGY_LOG_LOCALS=1 PRODIGY_LOGGING="basic" python -m prodigy ner.manual my-dataset blank:en examples.jsonl --label foo
11:44:37: INIT: Setting all logging levels to 2011:44:38: RECIPE: Calling recipe 'ner.manual'Using 1 label(s): foo11:44:38: RECIPE: Starting recipe ner.manual11:44:38: RECIPE: Annotating with 1 labels11:44:38: LOADER: Using file extension 'jsonl' to find loader11:44:38: LOADER: Loading stream from jsonl11:44:38: LOADER: Rehashing stream11:44:38: CONFIG: Using config from global prodigy.json11:44:38: CONFIG: Using config from working dir11:44:38: VALIDATE: Validating components returned by recipe11:44:38: CONTROLLER: Initialising from recipe.11:44:38: VALIDATE: Creating validator for view ID 'ner_manual'11:44:38: VALIDATE: Validating Prodigy and recipe config11:44:38: CONFIG: Using config from global prodigy.json11:44:38: CONFIG: Using config from working dir11:44:38: DB: Initializing database SQLite11:44:38: DB: Connecting to database SQLite11:44:38: DB: Creating unstructured dataset '2023-04-04_11-44-38'11:44:38: FEED: Initializing from controller11:44:38: PREPROCESS: Tokenizing examples (running tokenizer only)11:44:38: FILTER: Filtering duplicates from stream11:44:38: FILTER: Filtering out empty examples for key 'text'
================================= Traceback =================================
File "/opt/homebrew/Cellar/python@3.9/3.9.16/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 197, in _run_module_as_main return _run_code(code, main_globals, None,File "/opt/homebrew/Cellar/python@3.9/3.9.16/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 87, in _run_code exec(code, run_globals)File "/Users/username/dev/prodigy/__main__.py", line 62, in <module> controller = recipe(*args, use_plac=True)File "/Users/username/dev/prodigy/core.py", line 393, in recipe_proxy return Controller.from_components(name, components, config)File "/Users/username/dev/prodigy/core.py", line 75, in from_components return cls(File "/Users/username/dev/prodigy/core.py", line 174, in __init__ self.feed = Feed(File "/Users/username/dev/prodigy/components/feeds.py", line 115, in __init__ self._stream, self._original_data = self._init_stream(File "/Users/username/dev/prodigy/components/feeds.py", line 162, in _init_stream stream = Stream(data, total=original_total, count_stream=auto_count_stream)File "/Users/username/dev/prodigy/components/stream.py", line 110, in __init__ self._start_count(data)File "/Users/username/dev/prodigy/components/stream.py", line 116, in _start_count self._data = self._get_buffer(data, self._first_n)File "/Users/username/dev/prodigy/components/stream.py", line 135, in _get_buffer item = next(data)File "/Users/username/dev/prodigy/components/preprocess.py", line 172, in add_tokens for doc, eg in nlp.pipe(File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1530, in pipe for doc in docs:File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1574, in pipe for doc in docs:File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1571, in <genexpr> docs = (self._ensure_doc(text) for text in texts)File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1520, in <genexpr> docs_with_contexts = (File "/Users/username/dev/prodigy/components/preprocess.py", line 165, in <genexpr> data = ((eg["text"], eg) for eg in stream)File "/Users/username/dev/prodigy/components/loaders.py", line 48, in _add_attrs for eg in stream:File "/Users/username/dev/prodigy/components/filters.py", line 50, in filter_duplicates for eg in stream:File "/Users/username/dev/prodigy/components/filters.py", line 21, in filter_empty for eg in stream:File "/Users/username/dev/prodigy/components/loaders.py", line 42, in _rehash_stream for eg in stream:File "/Users/username/dev/prodigy/components/loaders.py", line 205, in JSONL msg.fail(err_title, err, exits=1)
============================== Warning message ==============================
✘ Failed to load task (invalid JSON on line 2)This error pretty much always means that there's something wrong with this lineof JSON and Python can't load it. Even if you think it's correct, something mustconfuse it. Try calling json.loads(line) on each line or use a JSON linter.Example output of traceback with locals
> PRODIGY_LOG_LOCALS=1 PRODIGY_LOGGING="basic" python -m prodigy ner.manual my-dataset blank:en examples.jsonl --label foo
11:44:37: INIT: Setting all logging levels to 2011:44:38: RECIPE: Calling recipe 'ner.manual'Using 1 label(s): foo11:44:38: RECIPE: Starting recipe ner.manual11:44:38: RECIPE: Annotating with 1 labels11:44:38: LOADER: Using file extension 'jsonl' to find loader11:44:38: LOADER: Loading stream from jsonl11:44:38: LOADER: Rehashing stream11:44:38: CONFIG: Using config from global prodigy.json11:44:38: CONFIG: Using config from working dir11:44:38: VALIDATE: Validating components returned by recipe11:44:38: CONTROLLER: Initialising from recipe.11:44:38: VALIDATE: Creating validator for view ID 'ner_manual'11:44:38: VALIDATE: Validating Prodigy and recipe config11:44:38: CONFIG: Using config from global prodigy.json11:44:38: CONFIG: Using config from working dir11:44:38: DB: Initializing database SQLite11:44:38: DB: Connecting to database SQLite11:44:38: DB: Creating unstructured dataset '2023-04-04_11-44-38'11:44:38: FEED: Initializing from controller11:44:38: PREPROCESS: Tokenizing examples (running tokenizer only)11:44:38: FILTER: Filtering duplicates from stream11:44:38: FILTER: Filtering out empty examples for key 'text'
================================= Traceback =================================
File "/opt/homebrew/Cellar/python@3.9/3.9.16/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 197, in _run_module_as_main return _run_code(code, main_globals, None,File "/opt/homebrew/Cellar/python@3.9/3.9.16/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 87, in _run_code exec(code, run_globals)File "/Users/username/dev/prodigy/__main__.py", line 62, in <module> controller = recipe(*args, use_plac=True)File "/Users/username/dev/prodigy/core.py", line 393, in recipe_proxy return Controller.from_components(name, components, config)File "/Users/username/dev/prodigy/core.py", line 75, in from_components return cls(File "/Users/username/dev/prodigy/core.py", line 174, in __init__ self.feed = Feed(File "/Users/username/dev/prodigy/components/feeds.py", line 115, in __init__ self._stream, self._original_data = self._init_stream(File "/Users/username/dev/prodigy/components/feeds.py", line 162, in _init_stream stream = Stream(data, total=original_total, count_stream=auto_count_stream)File "/Users/username/dev/prodigy/components/stream.py", line 110, in __init__ self._start_count(data)File "/Users/username/dev/prodigy/components/stream.py", line 116, in _start_count self._data = self._get_buffer(data, self._first_n)File "/Users/username/dev/prodigy/components/stream.py", line 135, in _get_buffer item = next(data)File "/Users/username/dev/prodigy/components/preprocess.py", line 172, in add_tokens for doc, eg in nlp.pipe(File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1530, in pipe for doc in docs:File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1574, in pipe for doc in docs:File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1571, in <genexpr> docs = (self._ensure_doc(text) for text in texts)File "/Users/username/dev/venv/lib/python3.9/site-packages/spacy/language.py", line 1520, in <genexpr> docs_with_contexts = (File "/Users/username/dev/prodigy/components/preprocess.py", line 165, in <genexpr> data = ((eg["text"], eg) for eg in stream)File "/Users/username/dev/prodigy/components/loaders.py", line 48, in _add_attrs for eg in stream:File "/Users/username/dev/prodigy/components/filters.py", line 50, in filter_duplicates for eg in stream:File "/Users/username/dev/prodigy/components/filters.py", line 21, in filter_empty for eg in stream:File "/Users/username/dev/prodigy/components/loaders.py", line 42, in _rehash_stream for eg in stream:File "/Users/username/dev/prodigy/components/loaders.py", line 205, in JSONL msg.fail(err_title, err, exits=1)
=================================== Locals ===================================
{ 'err': "This error pretty much always means that there's something wrong " "with this line of JSON and Python can't load it. Even if you think " "it's correct, something must confuse it. Try calling " 'json.loads(line) on each line or use a JSON linter.', 'err_title': 'Failed to load task (invalid JSON on line 2)', 'f': <_io.TextIOWrapper name='examples.jsonl' mode='r' encoding='utf8'>, 'file_path': PosixPath('examples.jsonl'), 'line': '{"text": "notice that this line is not closing properly}', 'n_lines': 2}
============================== Warning message ==============================
✘ Failed to load task (invalid JSON on line 2)This error pretty much always means that there's something wrong with this lineof JSON and Python can't load it. Even if you think it's correct, something mustconfuse it. Try calling json.loads(line) on each line or use a JSON linter.Custom logging
If you’re developing custom recipes, you can use Prodigy’s log helper function
to add your own entries to the log. The log function takes the following
arguments:
| Argument | Type | Description |
|---|---|---|
message | str | The basic message to display, e.g. “RECIPE: Starting recipe ner.teach”. |
details | - | Optional details to log only in verbose mode. |
recipe.py
Logging data in the web app New: 1.18.0
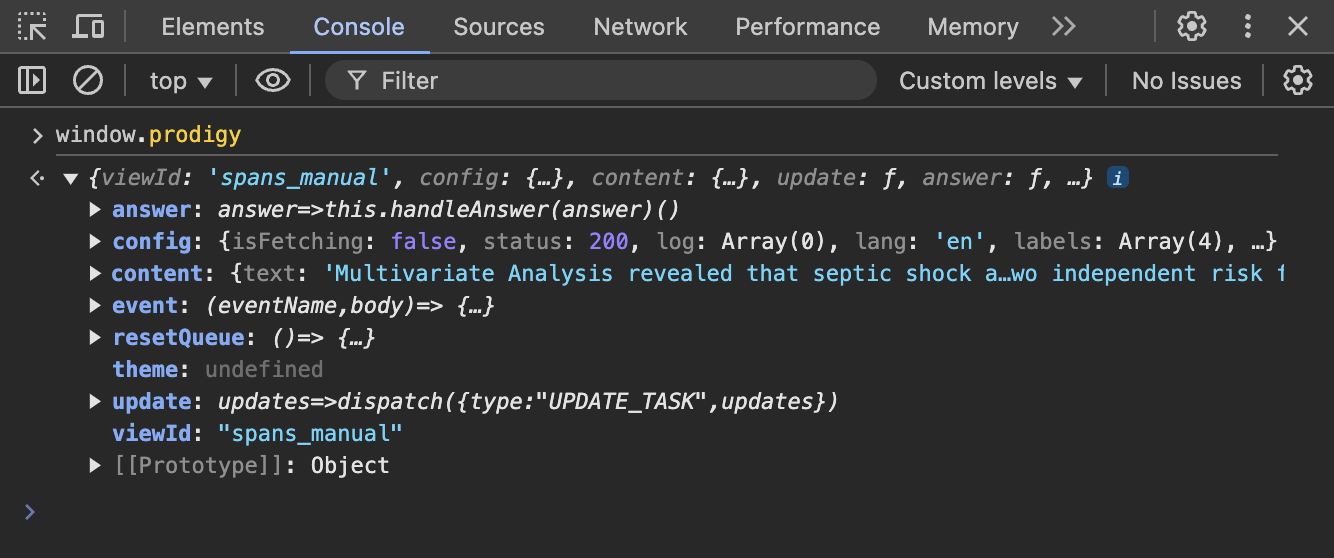
When developing custom recipes, interfaces and stream processing logic, it can be helpful to log and inspect what the web app sees. Prodigy exposes its data and actions via the global window.prodigy object, which you can access from your browser’s console. It includes the currently displayed task, as well as all global and interface-specific config settings:
Customizing Prodigy with entry points
Entry points let you expose parts of a Python package you write to other Python
packages. This lets one application easily customize the behavior of another, by
exposing an entry point in its setup.py or setup.cfg. For a quick and fun
intro to entry points in Python, check out
this excellent blog post.
Prodigy can load custom function from several different entry points, for
example custom recipe functions. To see this in action, check out the
sense2vec package, which provides
several custom Prodigy recipes. The recipes are registered automatically if you
install the package in the same environment as Prodigy. The following entry
point groups are supported:
prodigy_recipes | Entry points for recipe functions. |
prodigy_db | Entry points for custom Database classes. |
prodigy_loaders | Entry points for custom loader functions. |